优先级¶
fname = "data/2020/numpy_survey_results.tsv"
column_names = [
'website', 'performance', 'reliability', 'packaging', 'new_features',
'documentation', 'other'
]
priorities_dtype = np.dtype({
"names": column_names,
"formats": ['U1'] * len(column_names),
})
data = np.loadtxt(
fname, delimiter='\t', skiprows=3, dtype=priorities_dtype,
usecols=range(72, 79), comments=None
)
# Discard empty data
num_respondents = data.shape[0]
unstructured = data.view(np.dtype('(7,)U1'))
data = data[~np.any(unstructured == '', axis=1)]
glue('num_prioritizers', gluval(data.shape[0], num_respondents), display=False)
我们要求受访者分享他们对 NumPy 的优先级,以了解 NumPy 社区的需求/期望。用户被要求按优先级对以下类别进行排名:
for category in sorted(column_names[:-1]):
print(f" - {category.replace('_', ' ').capitalize()}")
- Documentation
- New features
- Packaging
- Performance
- Reliability
- Website
另设了一个开放式回答类别 (Other),以便参与者可以分享上述列表之外的优先级事项。
概述¶
在 1236 名受访者中,940 (76%) 名受访者分享了他们对 NumPy 未来发展的优先级。
为了了解每个类别的整体相对“重要性”,下图总结了根据排序选择投票的波尔达计数程序确定的每个类别的分数。
# Unstructured, numerical data
raw = data.view(np.dtype('U1')).reshape(-1, len(column_names)).astype(int)
borda = len(column_names) + 1 - raw
relative_score = np.sum(borda, axis=0)
relative_score = 100 * relative_score / relative_score.sum()
# Prettify labels for plotting
labels = np.array([l.replace('_', ' ').capitalize() for l in column_names])
I = np.argsort(relative_score)
labels, relative_score = labels[I], relative_score[I]
fig, ax = plt.subplots(figsize=(12, 8))
ax.barh(np.arange(len(relative_score)), relative_score, tick_label=labels)
ax.set_xlabel('Relative Borda score (%)')
fig.tight_layout()
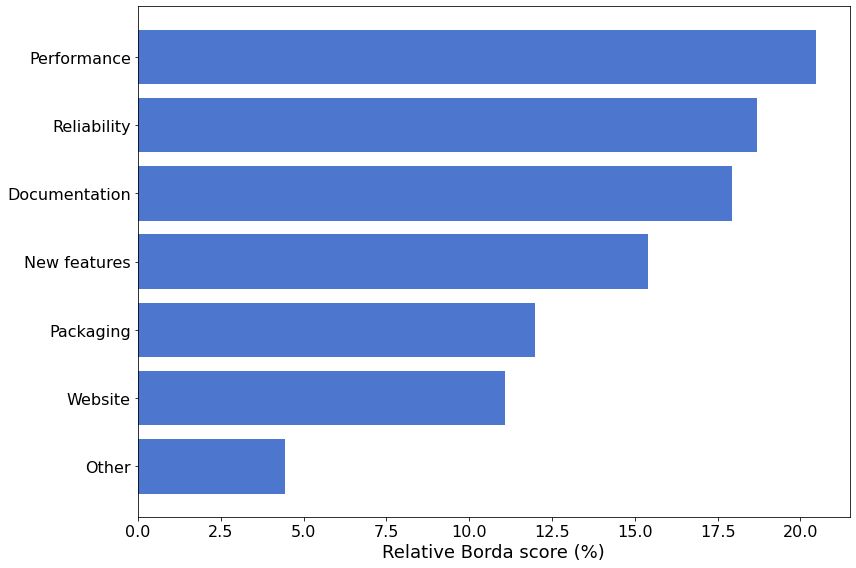
在首要优先级中,我们将仔细研究各项是如何被优先排序的。
首要优先级¶
下图显示了各项首要优先级事项的细分。
# Prettify labels for plotting
labels = np.array([l.replace('_', ' ').capitalize() for l in column_names])
# Collate top-priority data
cnts = np.sum(raw == 1, axis=0)
I = np.argsort(cnts)
labels, cnts = labels[I], cnts[I]
fig, ax = plt.subplots(figsize=(12, 8))
ax.barh(np.arange(cnts.shape[0]), 100 * cnts / cnts.sum(), tick_label=labels)
ax.set_title('Distribution of Top Priority')
ax.set_xlabel('Percent of Responses')
fig.tight_layout()
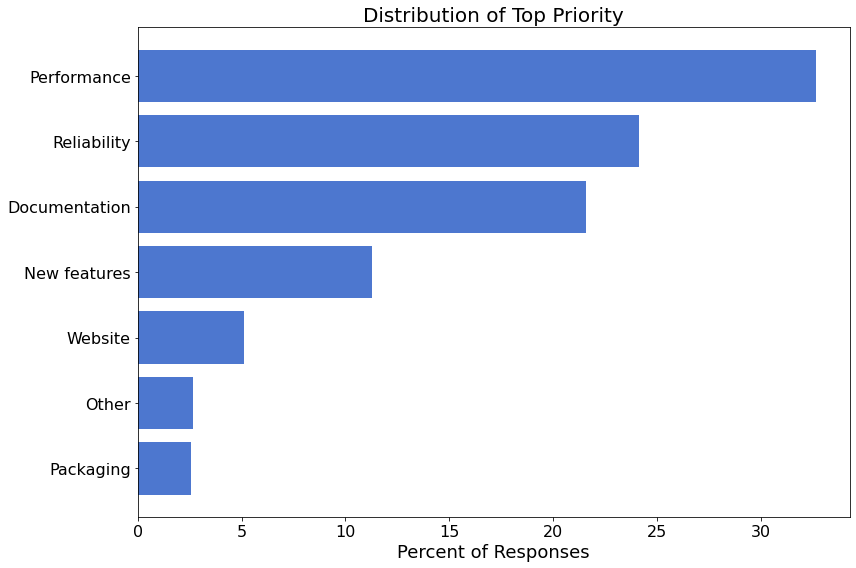
详情¶
我们要求分享了优先级的受访者,就他们的前两项优先级提供具体说明。例如,如果用户将“性能”列为首要优先级,他们会被要求分享关于如何改进性能的具体想法。各类别对应的回复如下。
categories = {
"docs", "newfeatures", "other", "packaging", "performance", "reliability",
"website",
}
# Load the text responses for each category
response_dict = {}
for category in categories:
responses = np.loadtxt(
f"data/2020/{category}_comments_master.tsv", delimiter='\t', skiprows=1,
usecols=0, dtype='U', comments=None
)
responses = responses[responses != '']
response_dict[category] = responses
# Generate nicely-formatted lists
for category, responses in response_dict.items():
gen_mdlist(responses, f"{category}_comments_list.md")
# Register number of responses in each category
for k, v in response_dict.items():
glue(f"num_{k}_comments", v.shape[0], display=False)
文档¶
170 名参与者分享了他们关于如何改进文档的想法。
点击展开!
评论 |
|---|
参考手册过于偏向编程。对我来说,缺少一个更偏向数学的说明。 |
更好的交叉链接以及更多指向 Python 和 C 级别源代码的链接 |
大多数函数的文档都非常出色,我能看出文档字符串(docstrings)受到了很多关注。然而,有些函数缺少一个应用示例。有时,我通过查看示例比阅读大量参数的冗长描述能更快地掌握一个函数。特别是在我最终甚至没有使用该函数的情况下,有示例会减少很多挫败感,因为我能立即看出这不是我想要找的。 |
说实话,NumPy 的文档可能已经是我用过的所有库中最好的之一了,但具体来说,如果能更容易地接触 NumPy 源代码就太好了。由于它是一个相当庞大且成熟的项目,很难知道从何开始,以及需要了解多少 Python C-API 才能感到自如。对某个人来说这可能工作量太大了,但我过去发现非常有用的指南是有人构建了一个项目的“最小版本”,这样你就可以看到库的核心(就像这个 SQLite https://cstack.github.io/db_tutorial/)——这也是我曾考虑在某个时候尝试对 NumPy 做的事情(只涉及核心数组结构,不包括线性代数等)。 |
提供更多常见任务的独立示例。通常我阅读文档并找到一个我正在尝试实现的操作的示例,但随后需要阅读其他几层文档才能理解该示例。 |
是的,我认为文档在学习者心中播撒种子方面起着关键作用,如果用户能找到更好的方式来全面理解该库中使用的类比和代码,那将是极好的。 |
更好的示例 |
我总是发现很难用 NumPy 的方式做事情,而不得不使用 Python 的方式。不确定能做些什么。 |
更多简单和中级的用法示例,以及关于新引入的令人困惑的随机数生成器变化的更清晰的文档和用法说明。 |
更多具体示例。不过说实话,StackExchange 可能已经很好地满足了这一目的。 |
为初学者提供更多基础知识 |
我猜是更多“初学者”内容。 |
更多教程和示例! |
更多示例 |
添加更长、叙述性的教程或案例研究 |
更多示例。通常示例非常简约(例如 numpy.fft.fft)。拥有更多示例有助于使用函数。 |
文档中增加更多示例 |
用“简单英语”解释函数的工作原理。 |
尝试使其更容易有效地找到信息,现在有些信息有时“隐藏”在额外的教程中。 |
我不认为有什么需要改进的,但我认为它应该继续尽可能保持一致性 :) |
例如,提供教程。 |
Jupyter notebook 示例 |
如何使用不常用功能,例如步幅(striding)、C-API 等 |
拥有一个完整且有组织的函数索引。另外,提供更多使用会显著改变行为的选项(例如 axis=)的示例。 |
每个非平凡功能都需要更多示例 |
更好的搜索功能 |
更多在不同情境下使用各个工具的示例 |
更多示例或操作指南。 |
在函数层面扩展代码示例。它们非常有帮助。 |
次要函数的文档和更多示例,更多关于性能优化的内容。 |
我经常使用结构化数组来读取二进制数据转储,并且将 C 结构体一对一映射到结构化数组的数据类型(dtype)将非常有帮助。我特别在想如何将 C 联合体转换为结构化数组。此外,Python 在我们公司越来越受欢迎,因此文档对我们来说是最重要的。 |
中级用法示例 |
如上所述。文档总是有帮助的,但 NumPy 的文档无论如何都相当不错。 |
它是好的,但有时很难找到我怀疑 NumPy 拥有的函数。文档树(doctrees)已经大大改进,但深入到具体函数可能会令人困惑。此外,许多函数如果对该主题是专家,其细节描述很好,但如果不是则不太好。一个很好的例子是滤波器设计函数。scipy.signal.butter 有一个名为“analog”的参数,其描述无益地写着“当为 True 时,返回一个模拟滤波器,否则返回一个数字滤波器。”区别是什么?我为什么要在意?scipy.signal.butter 的代码示例是另一个好例子,它们使用库的方式与我使用时可能大相径庭。(这更典型:https://stackoverflow.com/a/12233959/4492611)这并不是说文档不好,它们只是我与 NumPy 互动的主要方式,也是我最关心的话题。 |
* 为不同情况提供更多示例,而不是为多种方法只提供一个。* 此外,增加一个奇特的示例可能会拓宽人们的视野。 |
改进结构化概述,这样像我这样的“傻瓜”就不会尝试编写仅仅是 |
NumPy 库非常庞大,由于相当严格的向后兼容性保证,实现特定任务有许多不同的方法。我认为可以通过一个非正式的风格指南来改进文档,帮助新老用户理清什么是“现代”的 NumPy 方式。另一种选择(如果风格指南争议太大)是提供一套“现代”NumPy 用于完成常见任务并避免常见陷阱的示例。例如,线性代数集合可能包括使用 1D/2D ndarray 而非过时 matrix 类型,以及使用 @ 而非 |
以 scikit-learn 为例,也许可以提供更多关于如何操作的教程以及解释函数和实现背后理论和概念的文档。 |
文档中增加更多示例会很棒,有时我发现自己使用的函数解决了我的问题,但其用途并非来自文档,而是同事展示给我的。 |
NumPy 文档已经非常出色。我唯一的问题是,有时很难弄清楚所有现有的功能。我不确定具体如何解决这个问题。也许增加一些用户可以被引导完成整个问题集的用例会很有帮助(我知道这已经存在了,也许可以针对不同用例增加更多这样的内容)。 |
我首先要说,在我看来,NumPy 在自生成文档方面是黄金标准,项目中的每个人都应该对文档现状感到非常自豪。我发现有些情况下,更多示例会很有用。我有数值物理背景,我发现一些复杂数值算法的文档有所欠缺,尽管我现在能想到的例子都在 SciPy 中。对于复杂的数值算法,我认为仅仅文档化 API 是不够的。总会存在算法表现不佳或甚至返回错误结果的限制和边缘情况。文档在这方面可以做得更多。 |
更多示例和建议,我会借鉴 pandas。 |
组织文档肯定会有很大帮助。好的例子是 Docker 或 TensorFlow 的文档。另一个改进是为有兴趣为 NumPy 贡献的开发者增加更多指南。 |
某些科学文档还可以,但并非总是引用好的论文/网站。 |
对我来说,NumPy 曾经并且有时仍然有一个陡峭的门槛:我可以很容易地理解函数的基本用法,但要真正理解如何在复杂函数中以有效方式将函数应用于数据集可能很困难。我不认为这一定有一个简单的解决方案,但文档中更多样化的示例可能会有所帮助。 |
包含深入示例 |
- NumPy 和 SciPy 之间(以及不同版本之间)的文档有时有点令人困惑 - 在某些情况下,文档不足以理解函数的作用 - 有时我不确定是我找不到我正在寻找的正确方法,还是它根本不存在 |
我认为可以添加一些高级教程,特别是针对 NumPy 中较难理解的部分:- 步幅技巧 - 结构化数组和复杂的数据类型(dtypes)- 缓冲区协议集成(特别是与第三方库或自定义 C/C++ 代码库的集成)- 关于如何获得更好性能的文档(附有指向 Cython 或 Numba 等第三方库的提示) |
更多西班牙语文档。 |
扩展现有文档与基本数学模型之间的联系。目前文档的许多部分都有使用的概念摘要(如 FFT 中所示),但如果能有反向过程就更好了:一种可以从数学模型追溯到相关 NumPy 函数的文档。 |
即使阅读了文档,我有时也对函数中不常用参数的具体作用感到困惑。更多示例和更长的解释会有帮助。此外,NumPy 有很多功能,我经常发现很难确定某个问题需要什么。 |
添加更多关于 NumPy 在特定领域(物理学中的微分方程、生物系统的数学模型等)使用的示例。 |
所有算法/方法的文档都应该有适当的引用和各种示例(许多已经有了,但仍可改进)。 |
视频教程 |
所有函数都应该有类型标注,这样像 Pyright 这样的工具就能为用户提供更好的实时文档。 |
请添加更多循序渐进的教程(并在官方文档中直接链接到它们)。示例是理解新概念的绝佳方式。 |
有时很难找到文档,有时会找到旧版本函数的文档,但不知道它们是旧的,因此最好能明确哪些函数是当前的,哪些不是。另外,有时很难知道如何搜索某些函数。 |
教程,以及对一些人来说,翻译。 |
提供更多关于如何使用函数的示例 |
拥有母语信息很重要,尤其是在学习时。 |
它往往过于隐晦。我通常需要查阅其他资料来学习。 |
翻译成多种语言 |
更多针对初学者的教程,包含非常简单的概念,使用非常简单的术语,并附有大量解释 |
某些功能,例如 |
更多示例和教程。 |
对于新用户来说,文档内容过于密集。提供更多示例和应用,可能的话包括视频,以及练习集,也许在 Jupyter notebooks 中? |
许多方法缺少更好、更清晰的文档。 |
文档并非总是清晰地说明如何操作,而且有些术语充满了行话。 |
我希望看到更广泛的示例 |
我实际上认为你们的文档非常好,特别是与 Stack Overflow 的答案结合使用时。但我被要求选择一些内容! |
拥有多个(一致且集成)针对特定用户的文档系统会很有用。例如,语言级别规范与包含概念的温和介绍。 |
NumPy 函数的文档字符串(docstrings)风格不尽相同。 |
尽管这并非任何人的错,但旧的、已废弃的命令(尤其是在 SciPy 文档中)随处可见。简化 |
示例 - 大量 |
NumPy 文档中的许多高级文档页面不完整。例如,关于 dtypes 的文档没有列出所有可能的 dtype,也没有完整描述诸如字符串 dtype 规范之类的内容。 |
方便日本人理解如何使用 NumPy。 |
类型,更好的导航 |
更多操作指南 |
一件简单的事情是更新格式——我认为一些简单的样式表调整可以使文档本身更美观 ;) 组件之间更多的交叉引用(例如,“参见”链接 |
文档是任何事情最重要的部分。它让每个人都能阅读有关项目的数据和有用信息,并从技术上了解更多。 |
我认为包含指向 NumPy 更复杂用法(使用常见习语)的链接可能会有所帮助。 |
作为一名向同行介绍将 Python 用作科学工具的人,经常会提出关于 NumPy 的问题(例如如何执行特定操作,“陷阱”当实现特定函数时,或者对各种最小化工作示例的“食谱”有更普遍的兴趣)。尽管 NumPy 文档(特别是通过手册提供的文档)在一定程度上解决了这个问题(尤其是作为函数参数/输出/引用的快速参考!),但总有改进的空间:其中一个特别的方面可能是为“不那么简单”的示例提供更多例子,因为用户在实现时可能会在某些细节上出错。另一种可能性是在“解释”和“操作指南”页面中添加更多部分,以涵盖来自 Stack Overflow 等的常见问答(尽管我看到这是根据 NEP 44 最近才添加的,并期待看到它的进展!)。 |
关于在嵌入式设备上使用的文档(例如如何从 C++ 调用等) |
使文档更易于理解,并用通俗易懂的语言编写。 |
使其更像 scikit-learn 的文档 |
我想要更多执行示例。 |
也许当前采用“概述->函数->示例”格式的文档可以更明确。当你查找 |
更多基于案例的教程 |
更多“短篇故事”式的示例。总的来说,就是更多示例,既有直接的,也有在实际用例背景下的。 |
我希望看到更多示例,也许附带一些关于性能的参考。 |
是否可能为不常用函数添加更多用法示例? |
- 文档可能很难找到。例如,假设我去学习向量化。该页面(https://numpy.net.cn/doc/stable/)至少有六个不同的链接,用户可以点击这些链接来查找相关文档。选择其中一个,“教程”(https://numpy.net.cn/doc/stable/user/tutorials_index.html),又提供了一组链接,但没有提示其内容。最后,我不得不猜测我的主题会被归类为“NumPy 基础”。我认为这个导航系统应该重新设计。- 此外,许多文档页面需要对 NumPy 有相当深入的理解才能解读。 |
提供更详细的示例 |
如果能有更多关于 NumPy 中某些算法的实际应用示例/用例,那就太好了。 |
拥有以下内容会很棒:1. 更多初学者教程 2. 性能优化指南 3. 更多用法示例。 4. 制作一些在线沙盒,以便测试不同版本的示例 5. 目前大多数问题都可以通过 Google 找到答案。可能最流行的问题应该保留在文档中。 6. 我们需要一个 Slack/Discuss 平台进行讨论 |
参考文档已经很不错,但更多教程和更长的示例会很有用。 |
更广泛的示例。 |
更详细的示例和更好的错误消息。 |
一个针对不同用例的示例画廊,就像可视化库中看到的那样。 |
我实际上认为 NumPy 文档总体来说不错,但确保文档是最新的、解释充分并且尽可能提供多种语言,对于像 NumPy 这样重要的开源项目来说,应该始终是高度优先事项。 |
NumPy 的强大功能总是让我惊叹。我最近才发现库中包含金融函数。我发现很难发现大多数这些功能,除非我专门寻找某种东西,然后最终通过第三方平台(例如 Stack Overflow 告诉我我应该一直使用 NumPy 来完成这个任务)重新回到 NumPy。教程和带解示例是很好的参考资料,scikit-learn 社区是我不断从中汲取大量灵感的地方之一。 |
更多示例。 |
我N认为旧的“Eric 的广播文档”应该成为关于广播如何工作的核心文档的一部分,它非常出色,其中的图表非常有帮助。 |
更多示例代码 |
清晰的示例和指南 |
额外的示例更好的“未来将停用”错误消息:这些消息通常不提供任何替换它们的帮助,尽管我可能记错了,这可能是 Pandas 的错误。 |
更多示例。现有示例已经很多,文档总体来说也很出色,但在示例方面,它尚未达到 Mathematica 的水平。 |
如果您确实提供了对某些函数进行固有并行化的选项,那么需要编写使用这些功能的文档。否则,我认为文档没问题。 |
我N认为文档非常好且可靠。我希望技术部分和算法描述有更详细的叙述性文档。 |
更多来自 NumPy 使用领域的具体示例。并且将它们从入门级到经验级进行评级。 |
修复/更新不一致之处 |
也许可以提供更多带解示例 |
相关地,当其他包(如 pandas)的用户退回到可以用 NumPy 轻松优化的非常慢的设计模式时,经常会出现问题。为不经常考虑优化的用户提供更多关于将 NumPy 集成到以 pandas 为中心的工作流中的最佳实践文档可能会很有帮助。 |
有时很难完全掌握一个函数的具体作用以及它如何与 Python 的其他部分交互。 |
我认为更多/更清晰的示例可能会有效,有些未能完全解释函数。 |
更多示例。 |
教程 |
我想要关于次要函数的详细文档。 |
NumPy 文档可以为每个函数添加详细示例,这里的“详细”是指对输入和输出的更多解释。 |
文档通常不清晰或不完整。我认为 NumPy 的一些旧版本中的功能被重命名,这可能会令人困惑。 |
我希望您能包含一些图形示例,有时很难推断出数学原理。 |
插入更多使用示例,并提出一些对于长期用户来说很清楚,但对新用户仍可能造成困惑的问题点,例如切片时数组视图的情况。 |
尝试为每个函数提供不同的使用示例。 |
我是一个全新的 NumPy 用户。我希望能够找到我问题的答案。 |
我觉得 NumPy 的文档已经很不错了,但通常很难 找到 你正在寻找的正确文档。例如,通常有几个密切相关的函数,很难知道应该使用哪个(更难的是每次都不需要查找就能记住!)。也许增加一些方法,将文档片段与高层评论结合起来,说明“这是你通常应该使用的,除非你处于这种情况……”,这会有所帮助。 |
我喜欢 NEP 44 中的计划。当前的 (1.20.dev0)“绝对基础”和“快速入门”教程重复了大量相同内容,可能可以合并。“绝对基础”材料有 26 个章节标题,这使得其难以理解。我非常喜欢新网站首页突出显示“向量化、索引和广播”等主要概念,然后列出 NumPy 提供的一些子包的方式。也许这是我们入门文档可以遵循的提纲?我还在想,是否应该在新用户教程的中途引入多维数组,以便他们能更快地看到一些基本的数组操作? |
更多(以及更彻底的)代码示例。一个 HOWTO(像 Python 的 – https://docs.pythonlang.cn/3/howto/index.html)详细说明了常见问题的推荐解决方案。 |
在 DuckDuckGo/Google 中搜索 NumPy 函数时,通常首先返回旧版本 NumPy 的文档。请修复 SEO/删除旧页面,以便最新页面显示在顶部。 |
用例笔记本 |
更易于导航的索引 |
如果 NumPy 的文档能有小幅视觉更新就太好了(新网站很棒!)。pandas 项目有一个非常不错的新主题。另外,作为一名开发者,我非常喜欢 NumPy 的文档风格,并希望了解更多关于在自己的包中强制执行 NumPy 文档风格的工具。pandas 在其 CI 中有非常好的文档风格强制执行器,也许我应该在我的项目中尝试一下。 |
我仍然认为文档的完整性和特异性是 NumPy 最薄弱的环节。我认为用户不应该需要查阅源代码来验证某些功能底层数学的细节,但目前有时却需要这样做。 |
添加关于使用每个函数的最佳实践和/或最佳/次优方式的性能比较 |
保持良好工作。NumPy/SciPy 文档是一流的。 |
精简(更清晰地引导用户到文档的不同部分:教程、用户指南、API 参考)并使设计现代化。显然,改进许多部分的文笔。 |
更多教程。几乎所有文档字符串中都有大量示例。 |
文档已经非常好。对于初学者来说,更多示例代码和/或难以理解概念的视觉解释可能会有用。 |
像教程和高级主题的叙述性文档这样的高层文档状态不佳,并且数量不足。 |
API 文档的设计感觉很老旧。我希望您能设计成与项目首页一样的风格。 |
扩充日语文档。 |
像 statsmodels 一样,请丰富示例,提供数学背景和 Jupyter notebook。 |
更多解释事物功能和工作原理的示例,以及视觉解释,特别是在所有操作 ndarray 的地方。 |
文档可以更全面,例如包含案例研究。也可以涵盖关于 NumPy “基础”或“如何使用”的更简单的教程。许多初级用户不明白 NumPy 的范围在哪里结束,SciPy 的范围在哪里开始。 |
我希望对新引入的函数和方法进行注释。(为新函数或方法添加“引入版本”注释。) |
我认为建立一个将文档翻译成各种语言的项目是很好的。 |
创建各种类型的教育材料,考虑不同专业水平和经验的用户。 |
新网站是一个很好的改进。它所呈现的文档应该具有高度优先权,因为它是用户学习如何将 NumPy 功能融入其项目的基础方式。 |
1) 如果我用 Google 搜索某个 NumPy 函数,所有靠前的搜索结果都指向 1.17 版本而不是最新版本,而且没有简单的方法直接跳转到最新版本。 2) 我经常觉得文档只涵盖非常简单的示例,因此复杂用法并不明显。 |
更强的文档标准和自动化的文档字符串检查和验证,参考 pandas。例如,文档字符串中如何引用参数,是 |
NumPy 感觉目前处于一个相对良好的状态。剩下的空白应该尽快填补,特别是应该广泛使用示例。 |
文档是任何项目的核心。任何新手都会查阅文档,以便更好地理解软件/开源项目。因此,文档也应该得到同等的优先权。 |
总的来说,我发现文档非常好且全面。文档可以在以下两个方面改进:1. 为 NumPy 的某些功能包含更多“典型用法”指南。2. 更好地解释如果不知道可能会导致大量挫败感的细微细节,可能通过引用其他来源。 |
取得了长足进步,但为不同学科提供更多示例将有助于吸引用户。有些文档缺乏实际示例。 |
记录用户实际应使用的 NumPy 的(有限)部分 |
文档已经在很好地改进,保持下去 :-) |
总的来说,文档是好的,但说明函数的小示例有时有点隐晦。一句简短的描述性句子可能会有所帮助。// 作为开发者,如果参数被标记为例如“1.14 新增”,这也会很有帮助,这样我就知道根据我们的依赖约束是否可以使用它。 |
NumPy 文档功能齐全,能完成任务。然而,从 NumPy 项目开始到现在,更好的文档解决方案已经上线。NumPy 文档有一个奇怪的上一页/下一页主题界面,脱离上下文就毫无意义。一个功能齐全的左侧可滚动目录(类似于 readthedocs),以及更好的字体(我总是被主函数字体和黑/黄对比度的间距所困扰)。// 我个人最喜欢的文档外观是 Julia 和 Bokeh。 |
在文档中包含更多用例/边缘案例作为示例,例如,可以借鉴 Stack Overflow 中的常见用法。 |
只是一个轶事:我发现 |
LaTeX |
文档并不缺乏,但对某些包中示例作用的注释,特别是指出函数调用是为了速度或内存优化的地方,将使寻找我所需示例代码的体验更加顺畅。 |
尽管我确实喜欢这份文档,而且老实说,我应该多看它,而不是胡乱尝试或默认去 Stack Overflow 找答案(所以我的话听听就好!),但我认为,就像我回答上一个问题时说的那样,真正专注于人们如何最佳地使用 NumPy,而不仅仅是它的功能是什么,这将是极好的。 |
确保每个参数都有足够的文档。许多参数都被忽略了。 |
更多示例。 |
我认为文档非常好。但它可以更好,尤其是在提供为什么我应该使用一个函数而不是另一个功能相似的函数的上下文方面。 |
更多易于理解和使用的教程,介绍如何使用 NumPy 以及一些使用它的新工具,例如机器学习等…… |
无需离开网页即可更改版本(例如,从 v1.19 到 v1.18)。 |
研究和设计使学习和应用 NumPy 更有效的方法。寻求资金来研究和实施这些学习过程。 |
可以改进文档,以便对超过三个波段的图像执行操作。 |
几个函数缺乏良好的文档。了解其行为的唯一方法是手动测试,这可能很耗时。 |
新功能¶
75 名参与者分享了他们关于改进 NumPy 新功能的想法。
点击展开!
评论 |
|---|
不太确定,但它们是真正吸引新用户并重新激活现有用户群的命脉。 |
我希望看到 NumPy 支持自动微分(例如像 Jax 那样的 AutoDiff)。 |
如果 Stack Overflow 上的程序员找不到用 NumPy 解决其任务的方法,并且这种情况经常出现,那么这项任务必须提交给 NumPy,以开发新功能和可能性。 |
自动微分 |
我对 NumPy 了解不深,但我知道 NumPy 的一个强大竞争对手是 Matlab,因为它为工程师提供了许多简便的功能,这就是为什么许多人仍然留在 Matlab 而不迁移到 Python。只需几行代码就能运行数值模型、微分方程、优化和可视化结果的便利性,正是阻止一些工程师体验 NumPy 潜力的地方。 |
更方便地重载 NumPy 数组的运算符,例如将“+”改为直接求和,“*”改为张量积 |
实际上不太确定,只是肯定你们还有更多可以添加的。 |
分布式计算 CUDA 支持 |
GPU 支持,ndim 数组的不同放大/缩小方式 |
标准误差 |
接管 Biopython 使其更好。许多生物大数据分析流程仅限于 R。如果能在 NumPy 中完成就太好了。 |
支持物理单位 |
足够的频率滤波功能 |
小波支持。 |
GPU 支持 |
更好地支持大规模数据处理、惰性加载和读取多个文件 |
对底层功能有更多控制,并以不显眼但鼓励的方式记录函数的作用 |
添加对齐次变换的支持。它们是 4x4 矩阵,包含物体的位置和方向信息。它们在机器人技术中非常流行,如果 NumPy 中能有这样的支持将非常好。我需要从欧拉角构建这些矩阵,或者从它们中获取欧拉角,并且还需要能够对 6D 速度向量进行微分和积分运算。 |
没什么特别的。我认为 NumPy 非常棒,但如果非要选一个能让它变得更好的地方,那就是增加更多功能。 |
解除数组维度限制会很好。 |
CUDA 上的 NumPy |
* 一个可以轻松访问副本或原始数组的接口。有时无法确定。这需要简化。 |
我经常使用 NumPy 以向量化的方式运行简单的物理模型,即在 NumPy 数组上操作以一次计算许多解决方案。我发现很难编写既能接受单个浮点数又能接受 NumPy 数组的代码,经常会出现类型错误。我也有代码行为可能分岔成两种情况的情况。在这些情况下,我必须计算不同的东西并将它们存储在数组的不同部分,这是一个相当手动的过程。可能我不知道所有已经存在的功能! |
开发/推广围绕 |
拉普拉斯变换和控制模块。 |
优化 |
支持类型注解 |
GPU 支持 |
命名数组(像 PyTorch 的命名张量) |
在 f2py 中支持现代 Fortran(特别是派生类型和协同数组);使用类型注解指定 dtype (PEP 484)。 |
整数数组的 NaN 值(抱歉,我知道这不是 NumPy 的错)……新的数据类型(dtypes) |
更多机器学习实用工具,例如 PyTorch 和 TensorFlow 的接口。 |
- 更好地支持生成器和其他流式技术以最小化内存使用 - 更好地支持用户空间并行化(例如 multiprocessing.Pool.map 及其变体将很不错)。 |
扩展的张量代数会很棒。 |
代数拓扑算法会非常有用。几何对象也是如此。 |
原生 GPU 支持(像 CuPy,但更好地覆盖 NumPy 相关操作),更好地服务于机器人项目(例如导出到 ONNX 功能)。 |
更多信号处理函数。新函数。 |
支持有理数以进行精确线性代数计算 |
一种更容易定义新 ufuncs 的方法,以及 |
我希望有一种更好的方法来处理多维数组中的特定轴。目前我正在尝试使用 |
一种处理数据自动检测上下限的方法(例如计算包含“10<”值的数组的平均值)。一个包含上下误差界限的对象,以及处理它们的功能(例如获取对数值的误差,误差传播等)。 |
命名轴,基于命名轴的广播,性能诊断和检查工具 |
自动微分 |
用于查找最近索引的函数 |
不使用 NaN 标记缺失数据,即使用 NA 值。 |
稀疏矩阵,不规则数组 |
类型系统改进,以及一个像 numpy.api 这样的高级 API 命名空间 |
扩展函数式编程子包。 |
简易数据绘图 |
更多线性代数函数。 |
NEP-37 或后续改进 |
我希望看到更多线性代数功能,无论是现有 C 或 Fortran 库的封装,还是全新的开发。 |
更好地支持继承自 NumPy 的类 |
成为为扩展数组的外部项目设计 API 的核心要素 |
Twitter 上出现的一个功能是估计具有序列相关噪声的时间序列中的趋势。有很好的 C++ 包可用(例如 Hector http://segal.ubi.pt/hector/),但 NumPy 或 SciPy 中如果能有这样的函数将非常有用。 |
我对 NumPy 非常陌生,所以这个问题可能不合适。为什么 NumPy 数组中不能有字符串? |
能够使用 |
JAX 之外的自动微分,因为 JAX 可能仍然过于与 Google 生态系统/做事方式绑定。 |
推进与 NEP18 相关的开发 |
如果可用我会使用的功能(我已编写自己的代码来实现):- 保持凹性的受限样条拟合。- 翻译以 FORTRAN 格式编写的文本文件,其中包含没有“E”分隔符的带指数浮点值。 |
一个函数,用于只保留数组中的唯一数字并消除重复的,但不保留顺序。 |
命名数组 |
处理权重的函数,例如平均值,并将这些函数扩展到百分位数、标准差(std)、峰度(kurt)、偏度(skew)等。 |
与其他数值型GPU库集成——例如 PyTorch/MXNet |
高阶谱分析 双谱/三谱。(Original in Japanese: 高次スペクトル解析 バイスペクトル/トライスペクトル.) |
一种在多重循环中以与C语言同等内存和性能进行计算的功能。(Original in Japanese: 多重ループでの計算をC言語と同程度のメモリ、パフォーマンスで行う機能.) |
通过简单命令支持GPU |
轻量级JIT Python标记语言,类似于Halide语言,但只生成堆栈调用、缓存、本地化和循环。它仍然依赖于提供标量、SIMD向量的普通编译C函数,并且应该支持GPU和线程。其理念是减少内存和CPU缓存行程,只需一次内存加载和存储 |
- 更容易创建递推关系的快速实现,这通常通过循环实现。- 自定义步长实现。我经常处理球谐函数的数据结构,它们自然会用两个索引进行索引,其中一个总是正的,另一个是正或负的,但幅度小于第一个。类似于“普通”数组如何使用 stride[0]*idx[0] + stride[1]*idx[1] 映射到线性索引,我的数据可以使用 idx[0]**2 + idx[1] 映射到线性索引。目前我必须在两种方案中选择:一种是使用“普通”数组的简单实现,它提供了索引和广播的便利,但代价是存储大量零;另一种是使用直接作用于线性结构或将其包装在类中的算法的自定义实现。这两种自定义解决方案都无法让我使用NumPy中非常好的广播功能。我意识到这将对NumPy的工作方式产生巨大改变,但我认为这可以大大简化非“矩形”数据结构中的科学计算。 |
为NumPy添加静态类型 |
更好的稀疏/大型矩阵管理。尽管我猜测这属于SciPy的一部分,但它是一个非常重要的领域,应该认真考虑如何改进/扩展/加速整个稀疏基础设施。 |
更多种类的数学函数,可以在NumPy中实现。 |
关于PyData生态系统内更好集成/互操作性的功能。 |
在最近的NEP中提出的各种协议上持续取得进展,以支持与实现NumPy API的第三方库的兼容性。 |
整合Math 77库中的各种例程/函数,例如DIVA。 |
其他¶
21 名参与者将“其他”选为首要任务
点击展开!
评论 |
|---|
我认为这个项目非常出色,他们一直在进行的组织和规划也非常棒。(Original in Spanish: Creo que el proyecto es excelente y la organización y planificación que han venido llevando a cabo es muy buena.) |
静态类型。能够使用Mypy静态检查dtype和维度会很好,但即使是基本的静态类型支持也能改进文档(特别是结合Sphinx的autodoc功能)。理想情况是有一个足够强大的静态类型语言来描述可兼容数组:例如,my_func(a: m by n, b: n by k),但某种方式说明两个数组的dtype都可以安全地转换为float32。 |
对我来说,唯一真正高度优先的问题是正交索引,所有其他优先级都相形见绌。 |
我做的事情并没有真正缺少什么,这就是我选择目前不感兴趣贡献的原因。NumPy总体来说相当不错。 |
对我来说,GPU后端是NumPy应该追求的唯一也是最重要的目标。 |
uarray 和 unumpy |
我希望有一种方法可以告诉mypy期望的ndim/shape/dtype是什么,并且希望mypy能够利用这些信息找到一些错误。在理想情况下,这可以与 |
由于NumPy版本2似乎没有计划,我认为制定一个整合和清理NumPy API的路线图和时间表将非常有帮助。这与上面提出的非正式风格指南相关联。 |
有些东西已经为“2.0”准备了许多年……这么长时间的事实,我认为表明存在很多问题——我认为NumPy作为一个整体需要识别并解决那些严重阻碍他们的问题。 |
微Python对NumPy的支持,或许按模块划分会非常有用 |
支持大小的ndarray类型提示,以允许自动补全。 |
有NumPy教程吗? |
必须写出 |
与Numba、Cython和PyPy等其他项目合作创建JIT。 |
新的NumPy nditer C API尚未得到Cython的良好支持。事实上,如果能有一个高级的Cython接口,这样我就可以在Cython中(甚至可能在nogil中)使用nditer,而无需关心那些繁琐的C语言细节,那将是非常棒的。不确定这是否可行,但这会很酷。 |
NumPy在许多代码库中使用,因此打破向后兼容性很难。然而,NumPy中存在一些不一致之处,可以通过修复使其成为更好的库。我希望NumPy在引入破坏性更改时能更宽松一些,即使这意味着增加主版本号。 |
帮助CPython重构其C-API应该能为加速所有其他Python代码创造机会。但这只有在NumPy和SciPy等大型项目兼容的情况下才可行。这似乎是新的资助工作组可以帮助安排NumPy和CPython资金的领域。 |
定义和改进与其他库(例如PyTorch/Tensorflow/CuPy)的高性能互操作性。 |
对新贡献者的响应速度和第一印象良好会很有帮助。团队非常友好,但除非你已经很熟悉,否则很容易在所有开放的PR中迷失方向。 |
我目前在NumPy中遇到最多问题的一个普遍领域是自定义类数组类型以及可能扩展到自定义dtype。NEP 18为许多优秀的库间类数组类型兼容性(特别是对于我偏好的单位感知计算用例)开辟了道路,但仍有进展空间。两个例子是NumPy掩码数组无法与包装它们的其他类数组类型正常工作,以及单位-dtype数组(而不是子类或包装数组)正在持续取得进展。 |
与上述相关,我认为与科学Python生态系统(以及NumPy在该生态系统中的地位)相关联的最大担忧之一是,由于许多新数组库的引入而导致科学Python计算工具的碎片化。目前尚不清楚NumPy社区在这方面还能做些什么,而且已经致力于互操作性的工作非常有价值。我只想重申这项工作的重要性,并认为生态系统基于不同底层数组库而碎片化成多个生态系统将对整个科学Python造成损害。 |
打包¶
24 名参与者分享了他们对如何改进NumPy打包实用程序的看法。
点击展开!
评论 |
|---|
致力于像Anaconda那样的打包分发,但要独立。 |
我认为这更像是一个通用的Python打包问题。Conda、pip和apt-get(例如)之间的一切都感觉支离破碎,以至于我认识的许多人都在容器中运行所有东西,我感觉这只是在依赖性方面将问题推迟。 |
1. Conda在Windows上表现糟糕。需要更好的打包方案。2. 安装失败时提供更明确详细的错误信息。 |
提供单个功能特定安装,而不是一站式安装。为所有编程语言提供带有标准化输出(如JSON、XML、BJSON或其他格式)的包装器。 |
比过去好多了,偶尔仍然会出现编译时问题。 |
我希望NumPy的发行版尽可能地独立于操作系统。这样NumPy就可以在任何地方执行。 |
更多平台的wheels,例如aarch |
提议新软件包,以便在不同科学领域进行模拟和建模,并寻求与能够为每个软件包做出贡献的人进行合作。(Original in Spanish: Proponer nuevos paquetes con los cuáles se pueda realizar simulaciones y modelos en distintas áreas de ciencia, buscando colaboraciones con distintas personas que puedan contribuir a cada uno de los paquetes.) |
能够只分发NumPy选定的子模块(使用pyinstaller) |
更好地与setuptools集成。 |
为新的NumPy版本提供conda包。 |
Plotly |
确保可以通过pip和conda轻松安装在所有主要操作系统上。 |
arm64 wheels |
目前它已经相当不错了。我将其列为高优先级,以表明不应让任何较低优先级的项目危及安装的简便性。NumPy对于计算科学来说太基础了。 |
从源代码构建可以变得更容易。这方面的文档有点稀缺,使得很难找到所有可以和/或应该设置的旋钮。此外,对于哪个NumPy版本应该使用哪个Cython版本的依赖关系也会很有帮助。 |
将NumPy拆分成更小的包,如果应用程序不需要所有功能,则使用NumPy的应用程序会更小。帮助使像conda-forge这样的常规PyPI包成为现实。这将帮助小型项目在创建包含编译代码的包时利用相同的最佳实践。 |
NumPy构建系统的某些部分可以拆分为小的、可重用的包(例如多线程构建器)。我希望看到更多ManyLinux2014特殊架构(例如PowerPC)得到支持,尽管我最感兴趣的AARCH64现在已经包含在内,这很棒。 |
Pandas |
fftpack scipy.signal |
易于在任何平台上安装高性能版本。 |
我对新的发展不太了解,但我记得过去(大约2018/2019年)它通过环境变量获取依赖项的方式相当随意。文档也很薄弱,如果性能很重要,最好提供一些关于pip/conda版本仅针对基本的x86_64指令集,应该避免使用的建议。Intel-numpy是一个权宜之计,但NumPy文档中没有提及,我认为NumPy文档中更普遍的声明会更有帮助(适用于任何x86/ARM等供应商)。 |
关于BLAS与MKL的分发,这个问题对于不熟悉的人来说并非微不足道。 |
我觉得打包没问题。 |
性能¶
184 名参与者分享了他们对性能为何是首要任务以及如何改进的看法。
点击展开!
评论 |
|---|
我对NumPy内部的工作原理了解不多,但至少对我来说,性能是首要任务。 |
作为在专业和学术领域广泛使用的库,NumPy必须保证高性能和可靠性。(Original in Portuguese: Como NumPy é uma biblioteca de vasto uso tanto em âmbito profissional como acadêmico, é certo garantir alta performance e confiabilidade.) |
由于NumPy操作是许多程序的核心,任何性能改进都将对许多应用程序产生重大影响。NumPy绝不慢,但优化其性能会更好。 |
给 |
- 小型数组上速度慢 - 更好地与PyPy集成 - 为什么没有JIT / 或集成Numba - 更透明地访问GPU(尽管已经相当不错了) |
GPU 支持 |
使用Numba进行并行支持,函数向量化和速度改进,可能使用类似Arrow的东西实现。 |
许多功能可以使用Numba加速,如果能弥补这个差距会很好。 |
通过持续更新功能、强调关键学习目标、制作教程来改善用户群互动。 |
在整个库中对向量扩展提供适当和动态的支持,即当前版本的AVX等。NumPy应该自动检测CPU的能力并为每个操作选择最快的选项。 |
许多项目正在解决数据操作的性能问题。作为核心组件,保持性能至关重要。 |
更多的并行化和GPU支持。 |
我认为NumPy的性能非常好——对FFT后端所做的更改非常值得赞赏。我只是认为保持这种性能会很好——利用多线程操作会很好,但我知道这通常超出NumPy的范围,当我需要时我会使用其他具有类似NumPy API的库。 |
有些操作耗时过长。 |
没有特别的地方——我只是认为,鉴于现有的NumPy代码已经相当完善且文档齐全,性能是科学/数值库最重要的方面。 |
愿意接受任何可能的改进。 |
促进在需要高计算能力的操作中使用多线程或多进程。(Original in Spanish: Facilitar el uso de múltiples hilos o procesos para las operaciones que requieran alto poder de computo.) |
它应该始终是优先事项。对我来说,这就是NumPy的伟大之处。它很快! |
我希望能够使用GPU。 |
正如手动添加的那样,我认为GPU处理会有帮助。我在图像算法开发领域工作,所以主要处理图像数据(图像序列,因为我从事数字电影技术)。顺便说一下,性能并没有那么差,只是改进空间不大。 |
我实际上选择了“其他”和“性能”。由于我广泛使用NumPy进行图像处理,能够直接寻址GPU而无需CuPy等库是极其重要的,甚至可以说是关键的。 |
我相信Numba项目非常有前途,我非常希望看到Numba和NumPy之间更好的合作。 |
使Numba、Dask、Cython更易于使用。 |
你们做得很好,通过在文档和媒体上推广和解释功能,以及通过使用NumPy来理解和学习更深层次的抽象,从而与C++和其他高性能语言建立更多联系。 |
NumPy在性能上应与基于编译器的工具竞争,后者鼓励不那么优雅的编程风格。 |
并行处理,(可选地)利用专用硬件。 |
我收到关于NumPy与MATLAB性能的抱怨,大多数来自从未用过NumPy的人。我知道NumPy的速度和MATLAB差不多,但喷子总会喷,无知者总会无知。 |
提高计算效率,尤其针对大数组。(Original in Japanese: 提高计算效率,尤其针对大数组.) |
我编写的优化求解器在函数中需要进行许多小型矩阵-向量乘法,这些乘法不能合并到更高阶的矩阵操作中。我意识到这是一种相当小众的用例,但有没有办法降低调用开销?例如,在我的机器上,一个5x5的A与一个30x30的A进行Ax运算的成本实际上没有区别。我认为小型矩阵优化会大有帮助。另外,默认链接到MKL以外的东西。 |
也许可以与Numba进行集成,这样当你在数组上调用函数时,可以指定一个类似 how=numba 的参数。 |
潜在地包含GPU的使用。 |
指定固定大小的数组,以便某些函数运行更快。我经常处理小型矩阵,主要用于线性代数相关工作,因此如果能有针对特定大小数组优化的函数会很好。 |
没有特别之处。我认为作为科学计算的首选库之一,NumPy应该努力维护和提高其底层函数的性能,无论是对现有功能还是未来功能。 |
NumPy可以在GPU上运行吗? |
NumPy是机器学习的关键。性能是关键因素。 |
更多地使用并行计算。 |
能够在系统上可用且速度更快时,自动将某些操作交给Intel MKL、Blitz等库处理。 |
我没有什么改进的建议,但我觉得性能始终是最重要的,也是它被使用的原因。我非常乐意在任何被确定的开发优先级上进行协作。(Original in Spanish: No tengo ideas de como mejorar pero me parece que siempre es lo más importante y por lo que se lo usa. Me encantaría colaborar en cualquier prioridad que se tome de desarrollo.) |
我知道NumPy已经有很多向量化和并行化功能,但也许可以包含使用GPU或协处理器进行自动并行化。可能类似于JAX的做法,但内置于NumPy的一些核心组件中。 |
经过测试,使用NumPy进行索引比使用Numba的njit装饰器对相同函数进行索引花费更长时间。也许可以采纳一些对用户不可见的改进。(Original in Spanish: Haciendo pruebas, el realizar un indexing con numpy se demoró mucho más que la misma función pero con el decorador njit de numba. Tal vez se podría adoptar ciertas mejoras que sean invisibles al usuario.) |
抱歉,我没有想到具体的方法,我只是想表达对我来说最重要的是尽可能地提高性能。也许在线性代数库中加入并行化是一个不错的想法,而且执行起来也不太复杂。(Original in Spanish: Lamentablemente no se me ocurre como solo quise expresar que lo más importante para mi sería que mejoren cada vez que pueden el rendimiento. Probablemente incorporar paralelismo en las librerías de álgebra lineal sería una buena idea no tan complicada de ejecutar. ) |
使用更轻量级的实现,使其更接近Cython上的函数调用。但无需更改代码,易于启用和禁用。也许可以使用装饰器? |
默认的跨核心并行化选项。(Original in Spanish: Opciones de paralelizacion entre núcleos por defecto.) |
我没有任何建议,我只是认为性能应该优先考虑。 |
更多关于如何编写更高性能代码的解释。 |
我认为NumPy的性能非常出色,但我相信它应该继续成为关注的焦点。 |
我对此没有太多好想法,我只是认为性能最重要。 |
如果ndarray能像MATLAB或R中矩阵显示那样,会方便得多。 |
我之前使用IDL,当我用IDL编写相同的算法时,几乎总是更快。部分原因是,我比使用NumPy时更了解如何利用IDL中快速的部分进行编写,但即使我使用社区公认的最佳选项,它通常也更慢。 |
基于索引的准则和索引处的数据值同时进行数组选择的方法。 |
开发一种可移植的二进制文件存储格式,以便从不同语言(C、C++和Fortran)中使用。借鉴Pandas的理念并将其融入NumPy。Pandas与NumPy相比速度较慢,但比NumPy更健壮。 |
在某些计算中使用GPU。 |
整个库的性能非常好。只是就我的优先级而言,它是最重要的。 |
有些任务需要对数组进行多次遍历,但由于NumPy在某些查询中大量依赖掩码,这实际上是不必要的。Numba当然有助于缓解很多此类问题,但这只是NumPy核心设计缺陷的权宜之计。 |
没有太多可以改进的地方,我将其放在这里,因为它在更改/添加代码和功能时应该始终是最高优先级。 |
让一切都更快 :) |
让新用户更容易通过JIT或类似方式访问高性能代码。 |
NumPy的性能非常强大,其强大程度应该与文档和可靠性同等重要。(Original in Spanish: El rendimiento de numpy es muy potente y esa potencia debería de ser igual como en documentación y fiabilidad.) |
测量执行时间以寻找改进机会很重要。(Original in Spanish: Es importante medir el tiempo de ejecución buscando oportunidades de mejora.) |
通过并行化提高性能。(Original in Spanish: Mejorando el rendimiento por medio de paralelismo.) |
更多地支持并行编程、CUDA或自定义函数的向量化。 |
并行计算,改进算法。 |
GPU 支持 |
使用类似于PyTorch和JAX的代码加速(GPU、TPU)。(Original in Russian: Использовать различные ускорения кода (GPU, TPU). Например как в PyTorch, JAX.) |
性能很棒。它应该继续作为优先事项。 |
我在许多大型研究项目中都将NumPy作为基础库使用,其性能通常绰绰有余。一个挑战是如何对使用NumPy的大型程序进行性能分析。 |
让它“更快”! |
修复内存使用、限制以及对各种平台的支持。 |
JIT编译,轻松的并行/GPU支持。 |
改进内存访问关键操作。 |
原生分布式、多线程的NumPy。 |
我想我真的会为此考虑Numba和Dask…。 |
提高速度,设计直观易操作的函数。(Original in Japanese: 速度の向上、直感的に操作できるような関数の設計.) |
就我的用途而言,性能已经相当不错了——我只是认为应该保持下去。 |
已经很好了,但还可以更好。 |
用于处理和管理大型分布式数据。 |
GPU支持。 |
以约束方式处理大量计算的逻辑。(Original in Japanese: 大量計算を拘束に処理するロジック.) |
追求更好技术的竞争,总是由性能和可靠性取胜。这就是我将它们保持在较高优先级的原因。 |
添加类似Numba的JIT支持。可以提出一套特定的IR。 |
支持GPU。 |
添加GPU支持以加速矩阵运算。 |
多核和多线程的进一步改进。支持HPC使用的软件包。 |
我使用NumPy是因为它在大多数任务中都非常快。 |
总体速度提升。 |
例如,将np.min和np.max放在一个函数中。 |
复杂的表达式可能会在幕后创建临时数组。如果NumPy内部的巧妙编码能够消除这种情况就好了。 |
它是完美的。 |
NumPy在利用新硬件指令方面已经过时,还有很大的改进空间。 |
与下面的“新功能”一起:我希望有一种更好的方法来处理多维数组中的特定轴。现在我正在使用numpy.s_并直接调用getitem,但我对此不满意。它也不能在Numba编译的代码中使用,这限制了我。 |
我对这个话题没有太多想法。我知道在性能方面已经做了很多工作,而且更多的SSE/AVX向量化实现正在进行中。我想只要投入足够的精力进行基准测试、性能分析等,事情总能有所改进。 |
此外,更容易优化程序。(Original in French: Plus facile optimiser les programmes.) |
GPU |
核心API的显式标准化,以便其他工具可以作为并行或GPU计算的后端进行替换。 |
利用GPU。 |
集成Intel MKL和BLAS库的新功能。优化AMD Threadripper CPU等高核心数新处理器的性能。 |
也许通过Numba。 |
在可行的情况下自动利用多核。 |
更好地与基于深度学习的框架同步。 |
NumPy的微分方程求解速度很慢。 |
自动检测GPU,支持多线程。 |
异构操作。 |
更多关于性能最佳实践、技巧和窍门等的文档,将使其更容易获得可能已经存在但目前需要大量额外知识才能达到的性能。 |
如果NumPy能原生支持GPU会很棒,尽管CuPy基本上已经使大多数应用成为可能。如果能有更多分布式数组计算的选项会更好。 |
利用GPU加速(例如,允许使用添加了OpenACC指令的替代底层Fortran代码,即使仅用于某些常见操作) |
继续寻找执行代码的最计算效率高的方法。 |
围绕NEP-18的社区组织。 |
您可以提供一个单独的选项来内在并行化某些函数,和/或提供使用NumPy与其他可能提高性能的包的示例。 |
我不认为性能目前是一个问题。只是,我认为(总的来说)NumPy处于一个我没有什么可抱怨的状态,而且性能提升总是好的…… |
减少内存消耗。(Original in Spanish: Reducir el consumo de memoria.) |
更快的代码总是有帮助的。 |
并行化,GPU。 |
添加GPU支持。 |
NumPy应该使用Numba。 |
NumPy真的很快,我在使其更快方面经验不多。然而,我总是在代码优化方面依赖NumPy,我认为这是一个重要的资源投入点。 |
扩展的随机线性代数例程。 |
在GPU上自动执行。 |
我主要使用NumPy分析大型数据集。用NumPy加载这些数据集(高达2GB的CSV文件)并不是最省时的,而且会占用大量内存。 |
我对此主题一无所知,但我相信NumPy对科学界的主要用处在于其高性能。这应该继续成为一个优先事项。 |
在任何可以使用的地方启用GPU支持。 |
我有一个具体问题(并非纯粹与NumPy相关),那就是考虑到Julia和C++等其他语言的并行化很容易,我的Python代码很难并行化。 |
提供基准测试套件,我们可以在我们可用的平台上运行。Python,由于其性质(例如OpenCV接口),与其他平台上的相同操作相比速度较慢。这种劣势使其在主流IT部门中更难“推销”。 |
性能应该始终是首要任务。 |
我不确定。只要确保它表现良好就行。 |
确保它尽可能高效地工作。 |
相对于纯Python算法实现,性能是NumPy的关键价值主张。 |
性能问题主要集中在掩码数组上,它们可能非常慢。 |
识别当前算法高度次优的领域,或者存在性能更好的高级算法的领域。我在这里同时考虑NumPy和SciPy。例如,NumPy的中值滤波器比IDL等其他语言的实现慢得多,而且比最优算法慢得多。我上次测试时,NumPy的直方图算法非常慢。 |
向量化方面的工作听起来很棒。NumPy的一些部分也可以进行优化(例如2D规则分箱直方图)。据我所知,Windows版的NumPy尚未包含Unix所具备的表达式融合功能,这会很好。(Most these are just light-weight suggestions, I work further down from NumPy usually, but since so much relies on NumPy, performance gains can affect a huge community) |
1. NumPy用C语言编写的核心代码应该使用新的hpy API,这样PyPy(和其他Python实现)就有可能加速NumPy代码。2. 网站/文档中应明确指出,为了获得高性能,数值核心必须使用Transonic、Numba、Pythran、Cython等工具进行加速。详见:http://www.legi.grenoble-inp.fr/people/Pierre.Augier/transonic-vision.html |
我从事HPC工作,所以总是考虑性能。许多函数已经很快了,但速度越快越好。 :) |
我没有什么具体的想法,但越快越好 :) |
我很乐意看到NumPy成为事实上的数组计算API,其他包自愿选择允许互操作性。 |
总的来说,我对NumPy的现状相当满意,因此数值例程和聚合的通用性能提升仍然是继续改进NumPy的好方法。 |
如果NumPy中的FFT能达到“一流”水平,那将是非常好的。通常FFTW的性能优于KissFFT(我认为它是NumPy的基础),但由于许可问题,FFTW本身无法使用。 |
我对性能方向印象深刻——继续保持! |
改进与Numba和CuPy的互操作性。 |
超大数据集性能。 |
改进对内在函数/SIMD指令的支持。 |
原生集成GPU加速。(Original in Spanish: Integración de la aceleración por gpu de forma nativa.) |
我发现NumPy的性能非常棒。 |
关于如何以并行方式执行函数的指南、建议或用例。(Original in Spanish: Guías y recomendaciones o implementaciones para realizar las funciones de forma paralelizada.) |
并行化,SIMD。 |
处理大量数据的机会越来越多。希望它能再快一点。(Original in Japanese: 大量データの処理の機会が増えてきています。) 少しでも早くなることを期待します |
创建标准基准,以便进行评估。(Original in Japanese: 標準ベンチマークを作成して、評価できるようにする.) |
提高处理速度。(Original in Japanese: 処理速度を早くする.) |
加速向量化函数。(Original in Japanese: ベクトル化した関数の速度向上.) |
JIT编译器(可能类似于Numba/TorchScript)以允许“内核融合”,例如,使“for i in x: for j in y: for k in z: 对每个矩阵条目执行一些复杂操作”的速度变快。 |
NumPy的性能很好;然而,该项目“年久”。或许对基础代码进行重新设计会带来更好的性能。(Original in Portuguese: Numpy tem ótima performance; contudo, o projeto é “antigo”. Talvez uma reformulação no código básico traria uma performance ainda melhor.) |
并行计算支持、内存节省,或者整理相关文档以实现这些目标。(Original in Japanese: 並列計算の支援、省メモリ、あるいはそれらを行うためのドキュメントの整理.) |
改进伙伴库的使用或重构代码,旨在实现高性能并为量子计算做好准备。(Original in Portuguese: Melhorar o uso de bibliotecas parceiras ou códigos reformulados, visando performance elevada e preparação para uso em computação quântica.) |
让它更快更高效。 |
与做同样事情的其他库(甚至可能是其他语言的库)进行性能基准测试。 |
结合最新研究改进算法实现。 |
完成SIMD优化后,我正在考虑添加对OpenCL和CUDA的直接支持。 |
尤其是在处理超大数组时的速度。 |
没有具体的改进想法——只是我认为性能是NumPy如此有价值和广泛使用的基石(结合富有表现力的数组语法)。在我看来,NumPy保持高性能很重要,以防止随着许多新数组计算库(例如PyTorch)的引入而导致生态系统碎片化。 |
更广泛地使用多线程。 |
并非真的需要以任何特定方式改进性能和可靠性。但重要的是要保持它们,并像以前一样保持良好的性能。 |
与Julia进行基准测试。 |
我认为有关于使用更多向量化(通过SIMD指令)的想法,这看起来很有趣。更普遍地说,在多CPU使用和内存分配方面更好的性能总是值得追求的。 |
NumPy已经非常快了。但随着数据越来越多,NumPy在许多操作中必须更快。 |
将ARM兼容性和性能测试作为优先事项(考虑到macOS以及最近的超级计算机使用)。 |
增加向量指令(AVX、Neon等)的使用。使NumPy对Numba等JIT编译器更友好。 |
更快的小数组。 |
允许从所有平台进行SIMD访问,并迁移到超越manylinux2014的更现代的glibc。 |
持续进行ufuncs等的SIMD加速工作。 |
让它更快更好。基准测试优化。 |
全面集成SIMD和基于任务的多线程(例如TBB)。 |
继续你现在所做的。我不认为目前的性能有问题。 |
我没有具体的目标,任何能让它整体更快的东西在几乎所有情况下都很有帮助。 |
NumPy正在成为事实上的数据处理方式,它应该努力成为最好的工具。 |
为更多模块暴露C API,通过Cython使用。 |
多个低级后端(例如MKL)具有动态切换功能。OpenMP低级并行。 |
比较Python库random与numpy.random。在某些情况下,一个比另一个更好。例如,如果你想生成多个随机数,random.uniform更好;但对于从列表中采样,numpy.random.sample更优。如果NumPy始终更优,那会很好。 |
横向扩展,与其他库或数据类型的兼容性。 |
建立一个更强大、高度活跃的社区。我希望看到像TensorFlow那样的研讨会和会议。 |
在可能的情况下,无需或只需极少用户交互即可进行多线程或多进程计算。 |
目前没有性能不足,但持续优化库并宣称其已优化始终很重要。 |
我只是NumPy的用户(也是忠实粉丝!),但我对性能的看法是:/ 1. 人们没有高效使用NumPy,因此他们认为NumPy太慢,仅仅是因为他们的代码没有优化。这就是为什么文档和提供最优解决方案如此重要。/ 2. 我尝试使用CuPy,但我遇到了一些显卡问题,所以我的经验有限,但在NumPy中想要对某些功能提供GPU支持,这是否很疯狂或超出范围? |
我一直对性能改进感兴趣。它不需要我做任何工作,但我仍然从中受益。 |
线性代数模块可以有所改进(这不是我的专业领域,所以我不确定如何改进)。 |
我很乐意看到NumPy支持加速器和大规模并行(例如像JAX中的XLA)。 |
加快计算过程。目前,我们需要Numba、NumExpr或CuPy等其他包。如果无需任何额外包就能提速会很有趣。 |
可靠性¶
115 名参与者分享了他们对可靠性以及如何改进的看法。
点击展开!
评论 |
|---|
如果你想让人们使用这个库,可靠性是首要任务。 |
作为在专业和学术领域广泛使用的库,NumPy必须保证高性能和可靠性。(Original in Portuguese: Como NumPy é uma biblioteca de vasto uso tanto em âmbito profissional como acadêmico, é certo garantir alta performance e confiabilidade.) |
我认为无论如何可靠性都必须是首要任务。正确性必须比NumPy的任何其他方面都重要。我相信NumPy在这方面做得非常出色。我选择可靠性作为首要任务,希望继续看到这一点。 |
老实说,我只是给了它很高的优先级,因为这是我最近维护的代码中关注最多的方面,所以我认为它是任何库的关键卖点。就NumPy而言,我没有什么即时的建议。我发现我通常遇到的错误消息都非常有帮助,我很少会因为一些看起来与我实际尝试做的事情无关的错误而挠头。话虽如此,我确实认为与用户体验相关的问题应该被赋予非常高的优先级,因为NumPy是我所在领域(天体物理学)每个人都在使用的核心包,它的行为激励了许多需要卓越范例的初级开发人员。 |
扩展测试功能。 |
改进文档,以便人们为预期目的使用正确的函数。 |
NumPy仍然存在一些源于早期发展的不一致之处。这些应该被清理。 |
采用基于属性的测试。例如参见 https://doi.org/10.25080/majora-342d178e-016 |
再次强调,作为PyData生态系统的核心组件,可靠性和API一致性是强制性的,NumPy也因此而闻名。我将努力确保其可持续性。 |
已经很棒了。请通过谨慎和有节奏的开发,专注于测试和错误修复来保持这种状态。 |
有时错误信息过于模糊。 |
我认为NumPy非常可靠,我只是觉得保持这种可靠性很重要! |
到目前为止从未遇到过问题,但我认为它非常重要。 |
愿意接受任何可能的改进。 |
与性能一样。可靠性应始终是首要任务。作为许多广泛使用的Python库的核心,如果NumPy停止可靠,那将是一个大问题。 |
确保它与最新版本的Matplotlib和Pandas等保持兼容。 |
我希望NumPy能够成为一个易于安装和在任何机器上无障碍使用的库。我们可以提供一个API替代方案,在云端运行NumPy服务器,无需安装即可随时随地访问。包含更多功能以满足开发人员的需求。 |
统一一些功能几乎相同的函数;协调可选参数。(Original in French: Unification de certaines fonctions qui effectuent presque la même chose ; harmonisation des paramètres optionnels.) |
我认为它已经相当可靠了,但这正是我高度重视的一个特性。 |
我没有理由认为NumPy不可靠,但可靠性始终很重要。 |
它完全可靠,请保持这样。不要破坏向后兼容性。 |
保持高水平! |
减少bug。(Original in Japanese: 减少bug.) |
为所有输入和输出数据添加类型注解。 |
NumPy为许多关键的机器学习和深度学习奠定了基础。其关键功能应该没有bug。 |
我也没有想法,但我觉得这是必须具备的优势。我非常乐意在任何被确定的开发优先级上进行协作。(Original in Spanish: Tampoco tengo ideas pero me parece que es un fuerte que se tiene que tener. Me encantaría colaborar en cualquier prioridad que se tome de desarrollo.) |
对于非专业用户来说,理解浮点数精度等问题很困难。请记住,NumPy的用户很多时候没有软件开发背景。(Original in Spanish: Es difícil para un usuario no experto darse cuenta sobre precisión de números flotantes o similares. Considerar que muchas veces gente que no viene del área de la computación entra al mundo de numpy.) |
NumPy已经非常可靠。我只是想强调,在实现新功能或提高性能时,应保持这种质量标准,即可靠性与快速新功能/性能提升并重。 |
我没有任何建议,我只是认为可靠性应该优先考虑。 |
没有特别之处,只是它应该优先于大多数其他事情。 |
NumPy的可靠性很好。只需要保持下去。 |
提高现有测试的可见性,并增加测试能力以显示版本间的数值稳定性。主要想法是,能够轻松地从用户测试中的异常行为追溯到我正在使用的NumPy组件的测试,从而快速区分问题的来源。(Original in Spanish: Mejorar la visibilidad de los test actuales y añadir capacidad de test para mostrar la estabilidad numérica entre versiones. La idea principal sería tener formas fáciles de trazar desde un comportamiento extraño en mis test de usuario a los tests de los componentes de numpy que estoy empleando para poder discriminar rápidamente el origen del problema.) |
目前,我对NumPy的可靠性没有意见,但这个特性应该成为未来开发的主要目标之一。此外,NumPy与许多其他模块/包(如PyTorch和TensorFlow)之间的互操作性应得到保证。 |
NumPy目前很可靠,但我认为它继续保持可靠性很重要。 |
对于科学和学术工作,可靠性是关键。当一个计算需要几个小时/几天才能完成时,NumPy必须可靠地工作。而且它已经做到了——至少我从未遇到问题。然而,在更改/添加代码或功能时,这一点应始终予以考虑。 |
让arrange更精确,例如如果我设置numpy.arange(-1,1,0.001),有时它会达到0.5000000001或0.499999999的值,而不是0.5,所以有时arrange不那么精确,这不是什么紧急的事情,但如果在某些操作中能更精确会很好。(Original in Spanish: Hacer más exacto un arrange, por ejemplo si pongo numpy.arrange(-1,1,0.001), a veces puede llegar a valores de 0.5000000001 o 0.499999999, en vez de 0.5 por lo que a veces los arrange no son tan exactos, no es algo tan urgente, pero sería bueno que pudieran ser más exactos en ciertas operaciones.) |
使API尽可能地向后兼容。 |
NumPy是我使用过的最可靠的软件包之一。我从未遇到升级到新版本的问题,也记不起曾遇到过NumPy的bug。非常感谢这种质量。 |
可靠性目前很好。我只是建议可靠性应继续作为优先事项。 |
继续做好工作。 |
说实话,我对NumPy目前的状况非常满意。我没有任何抱怨!但我在上一张幻灯片中无法表达这一点。所以,如果我必须选择一个优先级,可靠性通常是我的最高优先级,因为我们在生产环境中使用NumPy。 |
指定数组的形状/步长对于使用pybind11从C++中使用NumPy数组非常重要。如果你对类型不非常小心,就会发生不必要的复制。尽管NumPy通常分配C风格的数组,但提前(在创建第一个数组时)获得保证将有助于避免过多的内存使用。 |
不要破坏任何东西 ;-) |
可靠性看起来也不错,但它需要持续维护。 |
掩码数组并非总是按预期执行。我不得不重写一些代码以不使用掩码数组,因为我得到了不正确的结果。这可能是文档问题或掩码数组的限制,所以我没有将其报告为bug,尽管它可能是一个bug。 |
能够支持和加载多个平台。 |
稳定API。 |
NumPy已经非常可靠,但在更新包时保持这种可靠性很重要(我很难对各项进行排序,因为NumPy已经能满足我所有需求甚至更多,相对易于使用,并且拥有我见过的一些最好的文档)。 |
我用NumPy进行计算。我需要知道它们是正确的。 |
可靠性已经很好。新的开发不应该破坏这一点。 |
我相信NumPy在我的工作和空闲时间都能按预期运行。 |
核心团队迄今为止在可靠性方面做得非常出色,请继续保持。 |
保持原样。(Original in French: Rester comme ce l’est.) |
使API更一致,以减少意外的bug。 |
对我来说,排名很困难。我应该说,我将可靠性列为高优先级,不是因为我认为NumPy不可靠,而是因为我认为可靠性是绝对关键的。 |
稳定的GPU API。 |
请不要引入回归。 |
与社区交流,从实际应用中创建新的测试用例。 |
确保小的版本更改不会破坏软件包的现有功能。 |
在检测到精度损失时提升到四精度。 |
沟通任何不向后兼容的更改。保持强大的测试标准,以确保新功能不会破坏现有代码。 |
我目前没有问题,确保对未来的更改进行详尽的测试将确保这一点保持不变。 |
减少破坏性更改。基于NumPy的工作的重现性不佳。 |
长期稳定性和向后兼容性。 |
我在使用NumPy的部分从未遇到过可靠性问题。我使用主流硬件。但我认为NumPy在技术栈中处于基础地位,因此可靠性至关重要且难以维护。请继续优先考虑它。 |
将可靠性解释为可重现性,避免不同平台(例如处理器)之间的数值差异。(Original in Spanish: Interpretando fiabilidad como reproducibilidad, evitar diferencias numéricas entre distintas plataformas (p.ej. procesadores).) |
更多一致性。 |
我认为澄清许多类似C语言的行为和边缘情况会有所帮助。可能对视图与复制之间的运行时发出警告。 |
没有,我不精通计算机科学,但我认为可靠性总体上应该是一个高度优先事项。 |
很好。只是不要为了新功能牺牲质量! |
请扩展NEP 18,因为NumPy API的清晰度对于在其基础上构建的库至关重要。 |
技术支持对双方来说都很困难。应通过提供具有可追溯当前状态日志的稳定解决方案,最大限度地减少对技术支持的需求。 |
我想知道我不会遇到它的问题。 |
可靠性(特别是在呈现长期稳定的API方面)是NumPy需要改进的地方。 |
在我看来,可靠性意味着减少因例如罕见数据情况或用户对函数语义的微妙误解而导致意外错误或错误结果的可能性。我认为自己对NumPy的内部结构或开发了解不够深入,无法真正提出改进可靠性的具体计划,但我 L想象更好的文档可以帮助防止用户执行他们未意识到“不安全”的操作。此外,可以添加更多的内置检查,尽管这当然需要与性能影响进行权衡。作为另一个部分涉及可靠性的增强,我将很乐意看到对缺失数据提供更好的支持。这是导致运行时错误的一个常见原因,这些错误在开发中不会立即被注意到,无论是在我的代码中直接出现还是将数据传递给其他库时。(我特别希望缺失数据功能能够与Pandas和生态系统中类似的部分很好地集成。)另一个非常不同的想法是,通过提供更官方的类型注解分发以及最终一个功能齐全的类型系统来增强对静态类型检查的支持,以便检查器可以强制执行数据类型和形状。 |
这里没有什么特别的——但关注可靠性总是一个好主意。 |
我没有任何具体建议,NumPy似乎已经高度可靠,但作为我大部分技术栈的核心包,我认为保持可靠性至关重要。 |
保持高标准! |
继续解决出现的bug。 |
关键业务决策可能基于使用NumPy的流程。因此,(数值)可靠性应始终是首要任务。 |
可靠性非常好,应该保持下去,不应因其他事项优先级提高而受到损害。这就是我将其排在第一位的原因。 |
我对可靠性感兴趣,因为不同版本的NumPy可能不兼容。 |
就像今天所做的那样(单元测试)。 |
dtype中的不一致。(Original in Spanish: Inconsistencias en los dtypes.) |
我很高兴内容高度可靠。我很高兴能够提供日文文档,但我希望在保持可靠性的前提下这样做。(Original in Japanese: 内容的な信頼度が高いと嬉しい. 日本語での文書提供が可能だと嬉しいが、信頼度を保ちながら行って欲しい.) |
修复bug! |
创建树形结构化的参考文档页面。(Original in Japanese: ツリーで構造化されたリファレンスページの作成.) |
评估软件开发中的安全方面,以避免开源代码被恶意利用。(Original in Portuguese: Avaliar aspectos de segurança nos códigos desenvolvidos para não permitir fácil invasão ou uso malicioso de código aberto.) |
确保其可访问性。 |
拥有多种自动化测试和高覆盖率的代码库。 |
确保快速处理和修复bug,提高在Windows和其他平台上的可用性。 |
可靠性与API一致性密不可分。最新版本使得一些表达式变得更难,尤其是在涉及对象数组时。有些规则很方便,但缺乏一致性——例如,len(numpy.array([[1,2,3],[1,2,3]]).shape) != len(numpy.array([[1,2,3],[2,3]]).shape) 这一点并不明显。 |
我不确定如何改进可靠性,但我相信可靠性必须仍然是NumPy的非常高的优先事项。 |
可靠性已经非常出色。它仍然是首要任务。测试覆盖率自然是关键。 |
NumPy在稳定性和可靠性方面做得很好,不确定如何进一步提高,它对于作为所有科学Python生态系统根基的包来说,似乎是一个重要的点。 |
我觉得NumPy相当可靠——我只是认为这一点必须优先于所有其他潜在的改变而保持不变。 |
通过使其可用于越来越多的编程语言。 |
NumPy通常在向后兼容性和更改的弃用过程等方面设定高标准。请继续保持。 |
没有什么异常之处,我觉得NumPy目前的可靠性状况很好。 |
测试,测试,还是测试。HPC世界中的架构数量正在增长,amd64的竞争对手有arm64和ppc64le。确保在这些平台上的可靠性至关重要。 |
强化NumPy将对所有人开放的承诺,考虑到最近提出的许可条款变更将引起行业大部分人对NumPy未来可靠性的担忧。就我个人而言,我将不再为NumPy做贡献,因为开源的本质将被扼杀。 |
我发现NumPy非常可靠。鉴于它在科学Python生态系统中的核心地位,我希望NumPy未来能保持同样的可靠性水平。 |
减少API表面和dtype怪癖。 |
Bug修复。更多单元测试。我的大部分代码贡献都是因为代码覆盖率不足而必需的。它们是边缘情况,但大多是显而易见的。 |
增加测试,插装模糊测试。 |
确保版本发布不会影响NumPy内部代码。 |
缩小范围:澄清哪些API受支持并弃用/移除边缘行为(例如索引)。 |
继续你现在所做的。继续保持良好的向后兼容性(我们测试的版本可追溯到1.14)。 |
我没有注意到任何可靠性问题——我只是认为它比其他方面更重要。 |
这里也没有什么新东西,NumPy是可靠的,我希望它能保持这样。 |
促进问题的发布,并寻找为解决这些问题提供资金的方法。(Original in Spanish: Facilitar la publicación de issues, y buscar formas de financiar la solución de estos issues.) |
在同一个解释器中对多个运行时(例如多个OpenMP实现)保持健壮性。这种情况确实会发生,并导致微妙的破坏。 |
NumPy已经相当可靠了 :) 我想错误字符串尽可能明确总是很有帮助的。我还发现,如果我不小心陷入了一个带有object dtype的NumPy数组(一个大数组保存在一个列表的列表中),那么要回到ndarray会变得非常混乱。我不得不递归地对子数组调用np.vstack,即使所有元素都是浮点数。 |
NumPy正在成为事实上的数据处理方式,它应该努力成为最好的工具。 |
一些微小的改变很重要(例如字符串表示)。当它们改变时,一些测试就会开始失败。 |
网站¶
最后,40 名参与者将NumPy网站选为首要任务,并分享了他们对如何改进的看法。
点击展开!
评论 |
|---|
Firefox上的字体太小,有大量空白。 |
ReadTheDocs,但不要使用默认皮肤。 |
numpy.org 的新设计看起来很棒,所以就继续保持下去吧。我认为总的来说,NumPy作为许多其他科学库的核心部分,并没有得到它应得的赞誉,所以我喜欢那些案例研究。 |
NEP 28 — numpy.org 网站重新设计 :) |
我上次查看主页时,无法进入实际文档。但自从我上次查看以来,它已经改变了。 |
普遍提高NumPy参考文档的可读性,例如像新的Pandas参考文档那样。 |
Material UI,更便捷的搜索,在Google中隐藏旧版本。 |
- 文档搜索结果不可靠/没有给出我想要的结果 - 合并SciPy和NumPy文档,或者更清楚地说明我需要哪个用于什么 - 在这里添加更多内容:https://numpy.net.cn/doc/stable/user/howtos_index.html |
更直观的目录。每个函数提供更丰富的示例,尝试利用函数的大部分参数。我认为新的Pandas网站看起来很不错,也会很适合NumPy的风格,但无论如何,内容优先于风格。 |
使用动画解释某些命令的功能,例如数组的处理。(Original in Spanish: Usar animaciones para explicar que hacen algunos comandos, como por ejemplo el manejo de los array.) |
让网站的文档部分看起来更现代化。使用更好、更易读的字体和更好的组织结构。减少白色调。它伤害眼睛。 |
使不同部分的总览和导航更便捷(也许通过放大顶部栏)。 |
请丰富教程。(Original in Japanese: チュートリアルを充実させてほしい.) |
更少的点击次数即可到达文档。 |
尽管互联网上有很多其他资源可以查找NumPy如何和为何做事的关键功能/实现细节/教程,但作为一个相当基础的软件包(尤其是在科学界!),拥有一个集中式的单一信息源(+一本实用的“食谱”,其中包含非单行代码)会非常有帮助,并提供用户友好的导航方式以查找相关信息(根据NEP 28)。这对于新用户(甚至是Python新手!)来说特别有用,我认为一个强大的网站将有助于展示其功能和实用性,以配得上这样一个基础且有用的工具! |
网站地图和导航辅助。 |
不确定,但我真的很喜欢新的变化 :) |
示例优先于严格的API文档。 |
对文档网站进行重新设计,否则我将无法摆脱它是一个非常古老的、被遗弃的工具的感觉。进行适当的搜索。目前,它只显示标题。 |
更新后的文档页面更易于导航。例如:在您向下滚动页面时,目录仍保持可见。 |
将在线文档更好地整合到新的网站品牌中。 |
我非常喜欢NumPy最近切换到自己的域名,以及新的主页。不过,文档似乎与新网站不协调:一个统一的主题会非常不错。最初开始学习NumPy花了我很长时间(主要是因为我没有扎实的线性代数背景,多维数组的整个概念没有立即让我理解)。 |
清晰的示例和指南 |
搜索功能有待改进;当搜索函数(例如np.repeat)时,如果只输入“repeat”,它返回的命名函数会比预期晚;此外,它还会返回各种位于其上方的结果,这可能会让新用户感到困惑。 |
一个具有现代外观和感觉的网站,适用于所有屏幕尺寸。 |
numpy.org的新主页看起来很棒! |
也许使其更现代化会吸引更多兴趣。让查找文档变得更容易,而不是总是依赖Google。 |
API文档、NumPy更高级功能的入门、常见性能陷阱部分(含示例)。 |
新主页看起来很棒。“文档”和“学习”部分提供了如此多的学习起点,以至于我不知道该引导新的Python用户从何开始。我理解这正在根据NEP 44进行改进。 |
更好的搜索,更方便地导航到子模块。 |
添加关于使用每个函数的最佳实践和/或最佳/次优方式的性能比较 |
最近的重新设计非常好,但还需要打磨。 |
在Google.co.jp上搜索“numpy”时,请想办法让官方页面在搜索结果中排名靠前。(Original in Japanese: 日本語でnumpyとGoogle検索をしたとき、公式ページが検索結果上位に来ない点をどうにかしてほしい。) |
没有具体的建议,但目前我很难找到我正在寻找的函数的解释。(Original in Japanese: 具体的な案はないが、現状では探している機能の説明にアクセスしづらいと感じている.) |
拥有大量教程的文档会很好。(Original in Japanese: チュートリアルが豊富なドキュメントが多いと良い.) |
我认为能够以多种语言浏览网站会很好。(Original in Japanese: 多言語でのウェブサイト閲覧が可能にするのが良いと思います。) |
复制TensorFlow,或者类似的东西。 |
更多示例 / 确保示例展示功能广度 / 网站上是否可以执行代码? |
更多文档。 |
NumPy的文档看起来枯燥乏味。它需要一个全新的面貌。 |
总结¶
下图显示了每个优先级级别上所列类别的选择相对频率1。
fig, axes = plt.subplots(3, 2, figsize=(12, 8))
for i, ax in enumerate(axes.ravel()):
priority_level = i + 1
cnts = np.sum(raw == priority_level, axis=0)[I]
ax.barh(np.arange(cnts.shape[0]), 100 * cnts / cnts.sum(), tick_label=labels)
ax.set_title(f"Priority: {priority_level}")
fig.tight_layout()
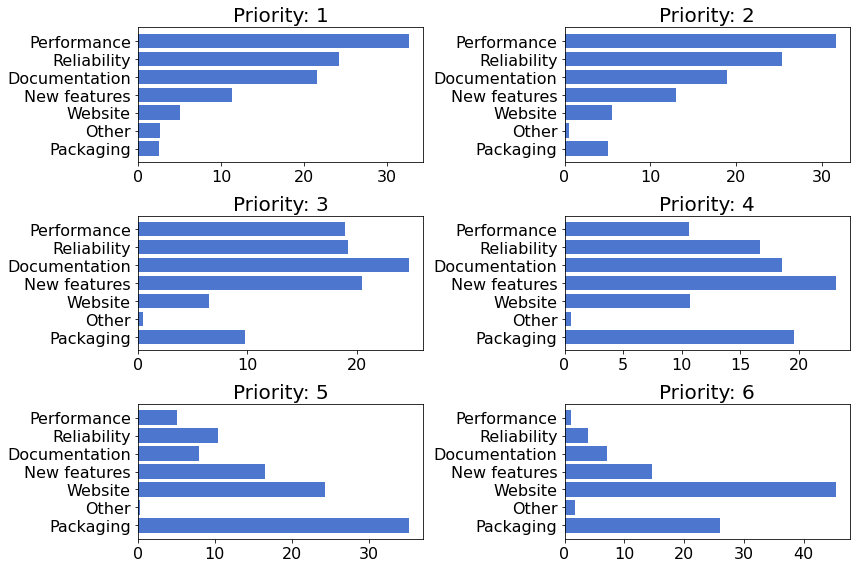
- 1
不包括
Other,这是一个可选类别,因此构成了“最低优先级”的大部分。